Memory Manager
In my previous post I described how I made my own Smart Pointers. This was a necessary first step towards creating my own Memory Manager, at least with the functionality I desired for my manager.
Overview
Let me describe a high level overview of a single execution using my manager.
We start with at least two empty
Heaps. A small one and a large one.

Whenever we allocate space, we try to see if the requested allocation will fit into the smallest
Heap first.

If an allocation won't fit into the smallest
Heap's free space, we try the next Heap until we get one big enough.
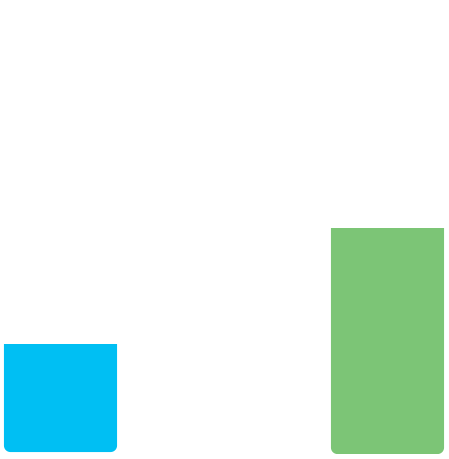
Eventually, our smallest
Heap is going to get filled up...
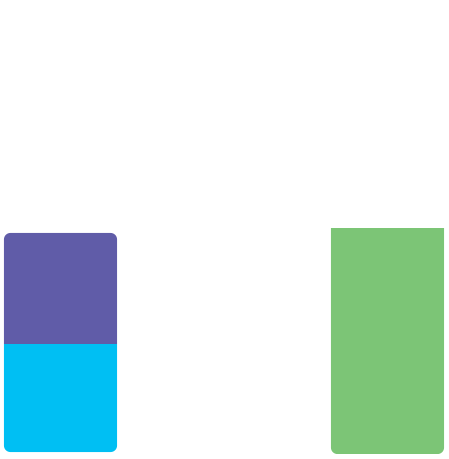
... in which case we need to graduate that memory up to the next largest
Heap.
Oh no! That just made our largest
Heap full. Now we need to graduate it too...
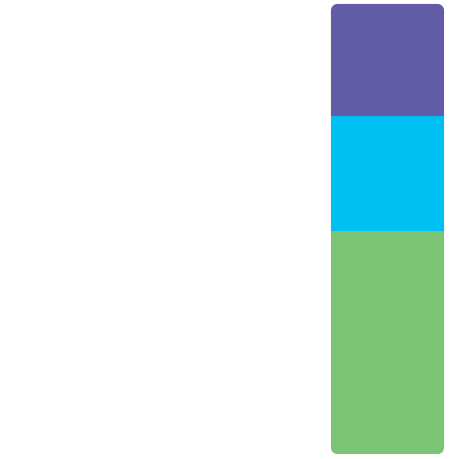
Since there is no larger
Heap we need to allocate one from the OS. We also could have pre-allocated all the Heaps we need if you know up-front the maximum amount of memory your program will need.
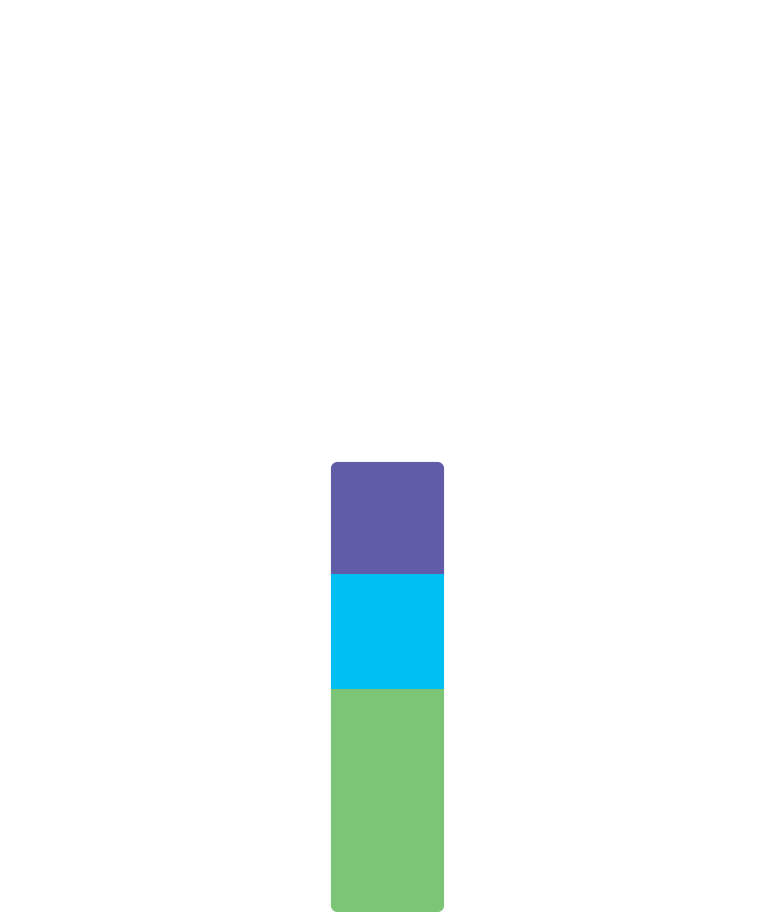
With the memory allocated, we can graduate our
Heap.

At some point, behind the Memory Manager's back, some memory can be released. This is done with no notification to the Memory Manager. No function is invoked on the Memory Manager. All that's happened is a flag has been set somewhere which the Memory Manager can observe on its own time.
We are now left with a fragment in our memory. This isn't an immediate issue. We can ignore it for now and keep allocating memory on top of the most recent allocation. However, that hole will remain and there's no way to reclaim that space until we defragment.

Whenever we feel like our memory has too many holes, we can defrag our
Heaps to reclaim that unused storage. This involves shifting all used memory down such that they are all contiguous. This leaves us with nice wide open chunks of memory that can be readily reserved to whatever needs it.

The reason we have progressively larger Heaps instead of one ginormous Heap is because we aren’t sure exactly how much memory our program will need at most. If we knew this for certain we could get away with one Heap while periodically defragging it.
The reason that the Heaps are progressively larger instead of the same size is because we don’t know the largest possible single allocation that will be requested. If none of the Heaps are large enough, we keep making new empty Heaps until one of them is finally big enough to fit the request.
I’ve decided to go with the smallest Heap being 1024 bytes and each successive Heap is twice the size of the previous (so powers of two). These decisions were completely arbitrary. Figuring out the perfect start size and scaling factor is a matter of performance benchmarking your specific application.
How do Smart Pointers fit into this?
Recall this graphic depicting how my Smart Pointers work.
SmartPtr itself has only one data member, a pointer to a Handle. The Handle stores the reference count and a pointer to the actual data. This double indirect is essential because the Memory Manager can go around shuffling memory behind your back. Every Handle shall henceforth be stored in a data structure that belongs to the Memory Manager. Whenever the Memory Manager moves memory, it fixes up the pointers in the Handles.
The Code
This is a long one. Be warned.
Changes to Smart Pointer
We need to add an additional data member to Handle: the alignment of this data. The Memory Manager has no access to compile-time type information. It’s just got bytes and pointers. With nothing to call alignof on, we need to store it somewhere. The Memory Manager needs to know about alignment for when it’s shifting data around. It can’t just plop an object into an odd address just because that happens to be the next free spot.
I was extremely happy about my Handle type being only 16 bytes. Since there’s a pointer in there, if we add an additional integer to store the alignment, we’re going to bring up the size to 24 bytes. Even if we use a 32-bit integer, we’ll get an additional 32-bits of padding. That feels like an immense waste considering that these Handles are so fundamental to our memory system. Every managed object will have one of them, so that’s 32-bits of wasted memory per object.
Luckily, there’s some hacks we can do. The alignment of any type in C++ will always be a power of two. That’s 1 bit asserted in an entire integer. We don’t need an entire integer to represent one bit, do we?
No, we don’t! Consider an alignment of 8. That’s \(2^3\) or 1 << 3. So we can store that alignment as simply the number 3, which only needs 2 bits. Assuming we’ll only ever make allocations of 1, 2, 4, or 8 byte alignment, 3 bits is all we need!
So realistically how big of an alignment will we possibly need? I don’t see us ever needing any alignment bigger than \(2^31\) or 1 << 31. 31 can be represented in as few as 5 bits, so that’s all the storage we need.
Now where can we steal 5 bits from our Handle? I believe the weakCount would be the least-used data type in most cases. Besides, if we steal 5 bits from weakCount that still leaves it with 27 bits. So we have a limit of \(134,217,727\) weak pointers to a single reference. I think we’ll manage.
struct Handle final
{
T* ptr;
uint32_t sharedCount;
struct
{
uint32_t alignment : 5;
uint32_t weakCount : 27;
};
};
If we wanted to even more things out we could have stolen 2 bits from sharedCount and 3 bits from weakCount. I’d prefer not to take up any bits from sharedCount because I believe that would be the more-used data member. Bitfields aren’t free. They add some (minor) additional code to deal with masking off the unused bits. For performance reasons, I’d like to leave sharedCount untouched.
We also need to refactor how we’re creating these Handles. Before, we were just calling operator new but now it’s the job of our Memory Manager to do that.
template<typename T>
template<typename... Args>
static SharedPtr<T> SharedPtr<T>::Make(Args... args)
{
return SharedPtr(Memory::Manager::Emplace<T>(std::forward<Args>(args)...));
}
This is the full extent of how much SharedPtr interacts with the Memory Manager.
We also need to remove some code from our destructors. Before we were calling operator delete on the Handle when there were no more references, but there’s no need for that now. The Handle’s lifespan is completely managed by the Memory Manager.
template<typename T>
SharedPtr<T>::~SharedPtr()
{
if (this->handle)
{
--this->handle->sharedCount;
if (this->handle->sharedCount == 0)
{
this->handle->ptr->~T();
}
}
}
template<typename T>
WeakPtr<T>::~WeakPtr() noexcept
{
if (this->handle)
{
--this->handle->weakCount;
}
}
Memory::Manager
The Memory::Manager (class Manager in namespace Memory) is composed of Heaps. The Manager itself doesn’t have much code. It merely invokes methods on each of the Heaps.
We define our Handle to be that which references a std::byte. We arbitrarily picked this because std::byte is exactly one byte big. We could have picked a bigger data type if we wanted that to be the minimum allocation unit. I wanted to waste no space, so I went with bytes.
We store our Heaps in a std::deque because the collection operations we need are:
- To access the
front. - To iterate through the collection.
- To
push_backandpop_backwithout invalidating any iterators or references. So astd::dequeis perfect.
Notice that on Alloc we never shuffle memory. This is supremely important. Alloc can happen at any time during execution, but we want to be very particular about when we Defrag or Graduate. Here’s an example of what could go wrong if we do.
- We’re iterating through a managed object.
- In the middle of this loop we call
Alloc. - There isn’t quite enough space but the
Memory::Managerfigures it can make enough room if it callsDefragorGraduateor both. - In doing so, the managed object has been moved!
- We return back to inside the loop and what happens next is pretty much undefined behavior, but it’s safe to say that the managed object’s iterator has been invalidated.
class Manager final
{
using Handle = SmartPtr<std::byte>::Handle;
friend Heap;
// Heap's ctor takes it's own index, which it uses to know how much space to allocate.
static inline std::deque<Heap> heaps{ Heap(0), Heap(1) };
template<typename T, typename... Args>
static typename SmartPtr<T>::Handle& Emplace(Args... args)
{
auto& ret = Alloc(sizeof(T), alignof(T));
new (ret.ptr) T(std::forward<Args>(args)...);
return ret;
}
static Handle& Alloc(size_t numBytes, size_t alignment)
{
for (Heap& heap : heaps)
{
if (Handle* ret = heap.Alloc(numBytes, alignment))
{
return *ret;
}
}
for (;;)
{
if (Handle* ret = MakeHeap().Alloc(numBytes, alignment))
{
return *ret;
}
}
}
static void Defrag()
{
for (Heap& heap : heaps)
{
heap.Defrag();
}
}
static void Graduate()
{
heaps.front().Graduate();
}
static void ShrinkToFit()
{
for (Heap& heap : heaps)
{
heap.ShrinkToFit();
}
while (heaps.size() > 2 && heaps.back().IsEmpty())
{
heaps.pop_back();
}
}
private:
static Heap& MakeHeap()
{
return heaps.emplace_back(heaps.size());
}
};
Where all the magic happens is inside each of our individual Heaps. Each Heap has a std::forward_list to all of the Handles it owns. These are the very same Handles that are pointed to by each instanced SmartPtr. For that reason these could not have gone inside of a std::vector or std::deque. We need to be able to perform random deletes in the middle of the collection without invalidating any references. They also need to stay in the order of allocation, so a std::unordered_set is out the window and std::set has additional overhead I’d prefer to avoid. That leaves only std::forward_list and std::list as viable options. I opted to avoid the additional overhead of std::list since it’s a doubly-linked list, even though std::forward_list is a bit more difficult to work with.
An ideal data structure to store the handles would be a custom Deque. The features we want in this Deque as opposed to std::deque are as follows:
- Each sub-array is of a configurable size. Perhaps the width of a cache line or some multiple thereof. This benefits the cache performance of my
SmartPtrby guaranteeing thatSmartPtrsdeclared at roughly the same time are more likely to be contiguous in memory. I believe this will help performance because it’s a reasonable assumption that data declared at roughly the same time is more likely to be used at the same time. - We don’t delete any
Handlesuntil allHandleswithin a sub-array are unused. This guarantees no references to aHandlewill be invalidated. The trade off here is that a long-livingHandlecould be dragging on a bunch of long-deadHandleswith it, leading to some bloat.
The key data members necessary for managing the memory we own are:
- the
beginpointer: the beginning of the memory we own - the
endpointer: the end of the memory we own - the
toppointer: the next available address to allocate at
index is only necessary on construction for determining the amount of memory we need to allocate and later on for finding the next Heap. A Heap* would have been just as adequate.
We also need to keep track of the largest alignment we’ve encountered for this Heap. This is necessary for when we Graduate this Heap’s memory to the next one. We have to ensure that all the memory we’re moving is properly aligned. Rather than checking each individual allocation to make sure they’re in the right spot, we can more quickly estimate by just making sure the whole chunk of memory we’re moving matches the largest alignment.
I’m not as worried about how many data members Heap has as I was with Handle. I expect there to be as many as thousands or millions of Handles at any given point, but hopefully no more than a hundred or so Heaps.
class Heap final
{
constexpr static size_t byteFactor = 1024;
using Handles = std::forward_list<Handle>;
Handles handles{};
std::byte* const begin;
std::byte* const end;
std::byte* top;
const size_t index;
size_t maxAlignment{ 1 };
public:
explicit Heap(size_t index) :
begin(std::malloc(byteFactor << index)),
end(begin + (byteFactor << index)),
top(begin),
index(index) {}
Heap() = delete;
Heap(const Heap& other) = default;
Heap(Heap&& other) noexcept = default;
Heap& operator=(const Heap& other) = default;
Heap& operator=(Heap&& other) noexcept = default;
~Heap() = default;
bool IsEmpty() const
{
return top == begin;
}
bool CanFit(size_t numBytes) const
{
return top + numBytes < end;
}
size_t TotalBytes() const
{
return byteFactor << index;
}
Heap* Next()
{
const size_t next = index + 1;
return next < Manager::heaps.size() ? &Manager::heaps[next] : nullptr;
}
Handle* Alloc(size_t numBytes, size_t alignment);
void Defrag();
void Graduate();
void ShrinkToFit();
};
Allocating space from a Heap is a very simple \(O(1)\) operation. There’s 3 main steps:
- We move the
topup just enough so that it satisfies ouralignment. topis now the address we’re going to return. Make aHandleto this address. Keep in mind the space saving trick we’re using to store thealignmentfor later.- Move the
topup so it’s pointing to the address just beyond what this object will need.
This operation can fail. The Memory::Manager will decide what to do then.
Notice that we emplace_front on our std::forward_list of Handles. This defines the order of our singly linked list. Newer allocations, which are also closer to top are in the front while older allocations, which are also closer to begin are in the back.
Handle* Heap::Alloc(size_t numBytes, size_t alignment)
{
const size_t offset = size_t(top) % alignment;
if (CanFit(offset + numBytes))
{
top += offset;
handles.emplace_front(top, std::log2(alignment));
top += numBytes;
maxAlignment = std::max(maxAlignment, alignment);
return &handles.front();
}
return nullptr;
}
ShrinkToFit is a nifty little function that can quickly free unused memory at the top of the Heap. It requires no shifting of memory, so it’s completely safe to call at any point in execution.
void Memory::Manager::Heap::ShrinkToFit()
{
while (!handles.empty() && !handles.front().Used())
{
top -= top - handles.front().ptr;
handles.pop_front();
}
}
If you’re scared of pointer arithmetic, don’t scroll any further.
Defrag can start by just calling ShrinkToFit. After that, we start at the top and work our way down by iterating through our singly-linked-list. After we’ve shuffled memory, we need to iterate through all Handles above this one to fixup their pointers. Due to the double loop this comes out to be an \(O(n^2)\) operation. Really not ideal. That’s a lot of memory we’re moving more than once.
There’s three ways we could get around this \(O(n^2)\) performance which I leave as an exercise to the reader:
- (Best option) We could implement a custom Deque as described previously.
- We could use a doubly-linked
std::listinstead of a singly-linkedstd::forward_list. This adds an additional pointer (8 bytes) of memory perHandle. I would advice against this. - We could simply
reversethe list before iterating through it andreverseit back afterwards. This is a lame \(O(n)\) operation but brings the overall complexity down. I do this inHeap::Graduateif you want to see an example.
When we shuffle memory, it’s important we call std::memmove instead of std::memcpy because the data could overlap and std::memcpy has undefined behavior in this case.
Also notice my use of [[likely]] and [[unlikely]] attributes within the loop. I’m telling the compiler that we probably have more Used blocks than unused ones and to generate branch prediction accordingly. This is simply my best guess and it could easily be wrong. Intuitively, it might make sense the other way. If we’re calling Defrag it’s probably because we have a lot of holes in our memory, right? So most blocks would be unused. Figuring out the right branch prediction here is tricky, dependant on your application, and requires profiling to discover.
void Memory::Manager::Heap::Defrag()
{
ShrinkToFit();
if (handles.empty()) [[unlikely]]
{
return;
}
// We're going to re-calculate this as we go.
// This is because the largest alignment required could have been freed.
maxAlignment = 1;
// keep in mind the list is in reverse order of allocation
// so next is the previous node but the next address
auto curr = handles.begin();
auto next = curr++;
while (curr != handles.end())
{
if (!curr->Used()) [[unlikely]]
{
// how big is this object
size_t byteCount = next->ptr - curr->ptr;
// shuffle memory
std::memmove(curr->ptr, next->ptr, top - next->ptr);
// adjust the top
top -= byteCount;
maxAlignment = std::max(maxAlignment, next->Alignment());
const size_t offset = size_t(top) % maxAlignment;
top += offset;
byteCount -= offset;
// done with this handle
++curr;
handles.erase_after(next);
// update the handles after this one
for (auto it = handles.begin(); it != curr; ++it)
{
it->ptr -= byteCount;
}
}
else [[likely]]
{
next = curr++;
}
}
}
Graduate is a much more efficient operation than Defrag. There’s only 4 major steps:
- Make sure the next
Heapcan fit the memory we’re going to give it. If not, it shouldGraduatetoo (we could also callDefraghere). - Copy all of our memory to the next
Heap. This is an \(O(n)\) operation but since it’s a bog standardmemcpyit’s probably the most efficient one possible in all of programming. - Go through all of our
Handlesand fixup their pointers. Another \(O(n)\) operation. - Give all of our
Handlesto the nextHeap. An \(O(1)\) operation.
We get to use the more efficient std::memcpy here instead of std::memmove because none of the memory should overlap.
This is where we use maxAlignment to make our copy more efficient. If we didn’t have maxAlignment, we’d have to individually copy every block, checking the alignment every time. The complexity would overall remain the same, but there’s still more operations. I’d rather memcpy the whole thing in one chunk.
void Memory::Manager::Heap::Graduate()
{
if (handles.empty()) [[unlikely]]
{
return;
}
// Get the next Heap.
Heap* next = Next();
// If there isn't one, make one (acquiring more memory from the system).
if (!next) [[unlikely]]
{
next = &Memory::Manager::MakeHeap();
}
// figure out exactly how many bytes we need
const size_t numBytes = top - begin;
size_t offset = size_t(next->top) % maxAlignment;
// Next Heap is too full, it must Graduate too.
if (!next->CanFit(offset + numBytes))
{
next->Graduate();
offset = size_t(next->top) % maxAlignment;
}
next->top += offset;
handles.reverse();
// update the handles
std::byte* addr = next->top;
auto nextIt = handles.begin();
auto currIt = nextIt++;
while (nextIt != handles.end())
{
const size_t byteWidth = nextIt->ptr - currIt->ptr;
currIt->ptr = addr;
addr += byteWidth;
currIt = nextIt++;
}
currIt->ptr = addr;
// copy the memory
std::memcpy(next->top, begin, numBytes);
next->top += numBytes;
next->maxAlignment = std::max(next->maxAlignment, maxAlignment);
// give up all of our handles
handles.reverse();
next->handles.splice_after(next->handles.before_begin(), handles);
// reset this Heap
top = begin;
maxAlignment = 1;
}
There’s a lot of room for tweaking and improvement in this Memory Manager, but most of that comes at the point where you’re benchmarking and profiling your application. It’s difficult to make decisions such as when it’s best to Defrag or Graduate when you don’t know how fragmented your memory is. But once those decisions are made, implementing them should be dead easy.
I think this Memory Manager is an excellent foundation for anything I might want to do. It’s very wonderfully flexible. I can make allocations faster than malloc when I want to while also making better use of memory than malloc at other times.
For now, this is where my adventures in creating my own custom game engine end. I haven’t even gotten into things like rendering or physics. Y’know, those quintessential components that come to mind when you think of a game engine. But there’s still so much that can be done at this low level before I get to those. I could easily spend another six months improving just what I have. I’ve learned so much and have built up an excellent repository of disjointed code that I can easily copy/paste whenever I might need some quick functionality in another project.
I’d like to say that I’ll pick this up again sometime, but we all say that whenever we shelve a project, don’t we?
Until next time!
You can find all the source code in this article on my repo.